Table of Contents
Introduction
HTTP is one of the fundamental building blocks for the Internet. It’s the protocol, or language, used to request and receive information from websites and other content sources over the Internet. In this blog, we’ll look at the security and performance improvements made to HTTP as it evolved over the past four decades. You’ll learn how HTTP operates, including the steps involved in HTTP requests and responses, the meaning being some of the most common status codes, and the roles and benefits of proxies. Finally, we’ll explore how DDoS attacks can be executed using HTTP, how to recognize an attack, and how to defend your organization.
What is HTTP?
Created in the early 1990s, HTTP stands for Hypertext Transfer Protocol and is a core component of everyday Internet use. Each time you type a website URL into a browser, click on a link, or click on a mobile web application on your phone, HTTP works behind the scenes to enable information exchange.
HTTP is a set of rules for how files – text, images, audio, and video – are transferred over the Internet. The protocol has advanced over time to meet the evolving needs of users. But its fundamental function has remained the same – to act as a language that enables us to interact with a website to get the information we need.
How does HTTP work?
HTTP is a client-server protocol that works at the application layer, or top layer of the OSI Model. It appears as the prefix in front of the web address, for example http://website.com, to instruct the web browser to communicate over the protocol. HTTP defines the request-response process that facilitates the information exchange with web-based applications. Requests are initiated by the client, usually a web browser, and the web server responds with the requested information.
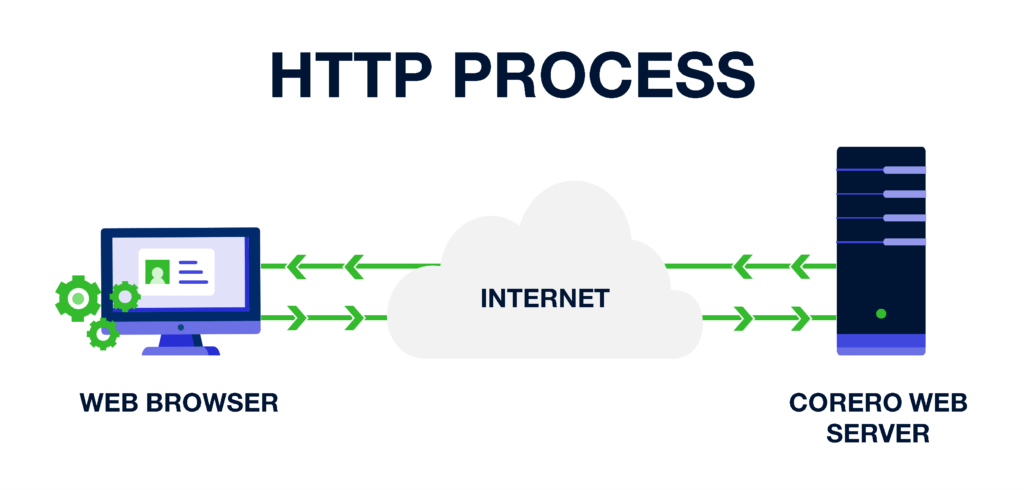
Using Corero.com as an example, the following steps are involved:
Request: A person types Corero.com into their browser or clicks on a link in an email or other communication. The browser generates an HTTP request. The request is sent to the server hosting that resource.
Response: The Corero web server processes the request and generates an HTTP response which includes the content on the Corero web page requested.
Data transfer: The response is transmitted back to the user’s browser using the HTTP protocol.
Display: The web browser renders the response message and displays the Corero web page.
What is an HTTP request?
Every time you type a website address into your browser or click on a mobile web application or link to access some sort of content, you’re launching an HTTP request. An HTTP request is the message a client (web browser) sends to a server asking for a specific action or resource. For example, this could include the information needed to load a website.
The process sounds straightforward. However, there are many components that makeup a request that users typically aren’t aware of:
- A request line consists of:
- the HTTP method (GET, POST, PUT or DELETE) indicating the desired action
- the target URL or resource path, indicating the location of the web resources
- the version of the HTTP protocol
2. A request header that contains additional information about the request:
- the browser type
- accepted content types
- user-agent information
- authentication tokens
- cookies
3. A request body is an optional component that sends additional information that is more likely to be included in a request initiated by an engineer or web developer. For example:
- a form to submit
- data to update a profile
- a file to upload
What is an HTTP response?
An HTTP response is the message the server sends back to the client to reply to the HTTP request. As with HTTP requests, HTTP responses also include several crucial elements in order to work properly.
- A status line that includes the HTTP version, status code, and status message.
- A response header with additional information about the response such as content type and length.
- A response body that contains the requested data including text, images, audio, and video.
Understanding HTTP status code
While it may sound esoteric, an HTTP status code is something you likely have encountered. Think about that “404 Not Found” message or “301 Moved Permanently.” These are examples of status codes that users receive in response to a request that isn’t successful.
Status codes fall into five main categories: informational, successful, redirection, client errors, and server errors.
Here are some of the most common status codes to be aware of.
200 OK. The request was successful, and the server provided the requested data.
301 Moved Permanently. The URL of the requested resource has been permanently changed.
400 Bad Request. The server cannot understand the client’s request.
401 Unauthorized. The client does now have proper authentication credentials to access a resource on the server.
403 Forbidden. The client’s identity is known, but they do not have permission to access the requested resource.
404 Not Found. The resource could not be found on the server.
500 Internal Server Error. The server cannot fulfill the request because it has encountered a condition it doesn’t know how to handle.
503 Service Unavailable. The server cannot handle the request. Often the situation is temporary and the result of a server being down for maintenance or temporarily overloaded.
What are the different versions of HTTP?
HTTP was introduced more than 40 years ago. The first version of HTTP was created in 1991 and was HTTP 0.9. HTTP 1.0 was introduced five years later, in 1996. Since then, new versions of HTTP have been released with the aim of improving speed, efficiency, and reducing latency.
HTTP 1.1
Created in 1999, HTTP 1.1 improved on the previous versions with innovations that increased how quickly requests could be sent, received, and responded to. Instead of requests coming in one at a time, HTTP 1.1 was able to batch requests. This not only reduced request processing time, but also cut down on overall traffic which decreased latency.
HTTP 2.0
HTTP 2.0 came about nearly a decade later and took advantage of technological advances in the intervening years to further improve the protocol’s efficiency, speed, and user experience. These innovations include the use of multiplexing, which allows for multiple requests and responses to be sent and received in parallel over a single connection. There is no need for separate connections to request and send text, images, and video. Compression is used to reduce the size of headers and further minimizes overhead. And, for the first time, clients can also prioritize requests.
HTTP vs HTTPS
One of the most significant advancements in HTTP was the introduction of HTTPS, with the “S” standing for secure. HTTPS adds a layer of security so that the sensitive and private information you need to transmit, like credit card numbers or banking information, is protected. HTTPS uses techniques including encryption and authentication to ensure confidentiality, privacy, and integrity.
- Data is encrypted so that it is protected in transit.
- The client-server connection itself is secured to further ensure the data remains private and not tampered with.
- The protocol authenticates that you are connected to the correct website to help ensure you haven’t been diverted to a different server which helps prevent malicious activity.
- If HTTPS detects that data has been tampered with, the server closes the connection and terminates the communication.
Proxies in HTTP
Proxies, or proxy servers, are application-layer servers, computers or other machines that go between the client device and the server and are primarily used to improve performance and/or security. Client requests pass through a proxy on their way to the server. And server responses pass through a proxy on their way back to a client.
Proxies can be transparent or non-transparent depending on the function they are performing. Transparent proxies don’t modify the request but send it on to the server in its original form. Non-transparent proxies are used to provide additional services that require some sort of modification to the request.
Web developers use proxies to:
- Save bandwidth and accelerate retrieval – caching or storing copies of web pages and resources to reduce the load on web servers and help clients access websites faster
- Authenticate users – enforce access policies to applications and online information
- Ensure privacy – hiding data, such as IP addresses of clients, to protect user data and browsing activity
- Restrict malicious or inappropriate content – controlling access to web pages that can compromise security or include inappropriate content
- Improve response time – load balancing client requests to the server so that they can be handled by multiple servers rather than just one
- Block suspicious traffic – filter traffic to protect servers from malicious activity, like DDoS attacks
Can DDoS attacks be launched over HTTP?
Imagine trying to enter a big-box store on Black Friday but instead of a steady stream of people, you’re faced with hordes of individuals all trying to enter at the same time. The same happens in a DDoS attack only the people are digital traffic, and the store is a website. In a DDoS attack, threat actors use multiple compromised devices to overwhelm a target server with an excessive volume of requests in the form of data packets, connection requests, and – yes – HTTP requests.
In fact, one of the main types of DDoS attacks are HTTP/HTTPS flood attacks. These attacks, fall into a category referred to as Layer 7 or application-layer DDoS attacks which seek to exploit vulnerabilities in the software or applications running on the server to cause a slowdown or complete service disruption. In the case of an HTTP flood attack, the HTTP internet protocol is being exploited.
If you’re seeing unusual traffic spikes to your website, a slowdown in response times, unexpected service disruptions or complete outages, an HTTP flood attack may be the culprit. HTTP flood attacks can be difficult to detect because they use standard URL requests that appear to be legitimate. Since these attacks require minimal bandwidth, they can go undetected for longer periods of time while inflicting significant damage.
To defend against HTTP flood attacks, organizations use a combination of best practices and technology, including content delivery networks, traffic monitoring and anomaly detection, rate limiting, load balancers, web application server connection limits, IP Blacklisting/Whitelisting, and DDoS protection.
Conclusion
Like Internet Relay Chat, HTTP was created in the early days of the online experience and has become one of the workhorses of the Internet to facilitate communication, even including status codes to inform users of operations. HTTP’s request-response flow organizes and simplifies data exchange and is an integral part of the infrastructure that powers our digital economy.
HTTP helps drive our digital experience and has evolved over the years to meet increased user expectations for performance and security. HTTP 2.0 uses multiplexing, compression, and prioritization to improve efficiency, save bandwidth, and reduce latency. As criminals have increasingly taken their craft online, the security capabilities in HTTP have advanced as well. HTTPS was introduced and includes security capabilities to protect the confidentiality, authenticity, and integrity of the communication and data exchange.
As with all components of the digital infrastructure, HTTP/HTTPS is not immune to attacks. DDoS attacks are surging in global volume and growing in sophistication, with HTTP/HTTPS flooding being one form of attack. Fortunately, the ability to defend against these attacks has increased as well. Together with improved security capabilities embedded in HTTPS, DDoS protection provides uninterrupted service availability even in the midst of a DDoS attack and can protect you from HTTP/HTTPS flood attacks as well as other types of DDoS attacks that threaten your operations.